Nagiosには、大規模ネットワークで1台のサーバーで は能力を超え てしまう場合や、ファイアーウォールの内部で外からの監視が出来ないようなケースのために分散監視の機能を有している。
システム構成のダイアグラムは、Nagiosのマニュアルにもあるように以下とおりである。
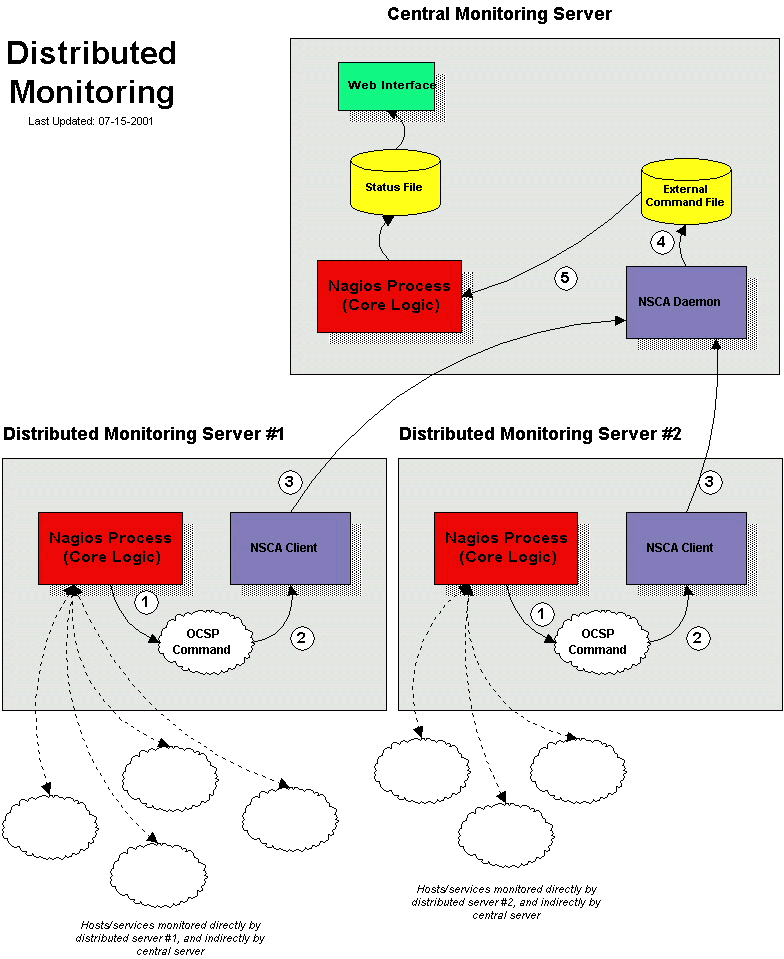
それを実現するには、監視を担当する分散サーバー(DMS)と、そのデータを集めて表示する中央サーバー(CMS)を設置することとなる。以下にその設 置方法を記す。
分散サーバ(DMC)の設定
じゃぁ実際の分散サーバのNagiosの設定は? 基本的にはベアボーンインストールである。Webインタフェイスや通知は必要ありませ ん。これらの機能は中央サーバに持たせます。 まずは、監視データを暗号化して分散サーバーから中央サーバーに転送するための別ページに述べるNSCAの
イン
ストールが必要。
続いて分散サーバーの設定であり、内容は以下の通り。
設定の変更ポイント:
① チェック対象となるホストやサービスを定義する。( hosts.cfg services.cfg hostgroups.cfg )
ここで の確認が重要。これが動かなければ元も子もない。
② スタンバイモードで起動するように設定する。( nagios.cfg ) enable_notification
③ obsess over service が機能するように設定する。( nagios.cfg )
④ ocsp コマンドを定義しておく。( nagios.cfg )
すべてを共に正しく稼働させるためには、分散サーバはすべてのサービスチェックをNagiosに送ることを期待する。
イ
ベントハンドラを使えば状態の変化をレポートすることしかできません。強制的に分散サーバにすべてのサービスチェックの結果を送信
させるには、メイン設定ファイルのobsess_over_servicesを
有効にし、サービスチェックの後に毎回 ocsp_command
を実行させなくてはならりません。中央サーバへ全サービスチェックの結果を送るために(上で記述した)
send_nscaクライアントとnscaデーモンを使ったocspコマンドを使用する。
設定を完了するために、以下のようなocspコマンドを定義する必要があります:
ocsp_command=submit_check_result
submit_check_resultコマンドののコマンド定義は次のような感じです。私の場合記入場所は hosts.cfg の最後あたりですある。define command{
command_name submit_check_result
command_line /usr/local/nagios/libexec/submit_check_result
$HOSTNAME$ '$SERVICEDESC$' $SERVICESTATE$ '$OUTPUT$'
}次にsubmit_check_resultシェルスクリプトであるが次のような感じにします(central_server部 分を実際の中央サーバのIPアドレスに置き換えてください):
#!/bin/sh
# Arguments:
# $1 = host_name (Short name of host that the service is
# associated with)
# $2 = svc_description (Description of the service)
# $3 = state_string (A string representing the status of
# the given service - "OK", "WARNING", "CRITICAL"
# or "UNKNOWN")
# $4 = plugin_output (A text string that should be used
# as the plugin output for the service checks)
#
# Convert the state string to the corresponding return code
return_code=-1
case "$3" in
OK)
return_code=0
;;
WARNING)
return_code=1
;;
CRITICAL)
return_code=2
;;
UNKNOWN)
return_code=-1
;;
esac
# pipe the service check info into the send_nsca program, which
# in turn transmits the data to the nsca daemon on the central
# monitoring server
/bin/echo -e "$1\t$2\t$return_code\t$4\n" | /usr/local/nagios/bin/send_nsca
-H 192.168.0.3 -c /usr/local/nagios/var/send_nsca.cfg
上のスクリプトではsend_nscaプログラムと設定ファイル(send_nsca.cfg)はそれぞれ/usr/local/nagios/bin/と/usr/local/nagios/var/ にある物と想定しています。
以上でリモートホストで稼働しているNagiosを分散監視サーバとして設定できました。では実際に分散サーバの挙動とどのように Nagiosへサービス チェックの結果を送っているのか見てみましょう(下の順番の番号は上のダイヤグラムの番号と連携しています)。
- 分散サーバがサービスチェックを終えた後、ocsp_commandで 定義したコマンドを実行します。ここの例では/usr/local/nagios/libexec/submit_check_resultス クリプトになります。 submit_check_resultコマンドの定義は4つの情報(サービスが属しているホスト名、サービスの 説明、リターンコード、出力)をスクリプトに引き渡すことに注目してください。
- submit_check_resultスクリプトがサービスチェック情報(ホスト名、説明、リターンコード、出 力)を send_nscaクライアントへパイプします。
- send_nscaが中央監視サーバのnscaデーモンにサービスチェック情報を転送します。
- 中央サーバのnscaデーモンがサービスチェック情報を受け取り、Nagiosが後に取得する外部コマンドファイ ルに書き出します。
- 中央サーバのNagiosプロセスが外部コマンドファイルを読み、外部監視サーバからのパッシブサービスチェック情報を処理しま す。
中央サーバの設定
中央サーバーは通常設定するようなス タンドアロンサーバ のような設定を行います。 その設定方法は次のようになります:
①
ウェッブのインターフェースが使えるように設定する。( cgi.cfg )
中央サーバーにおいてもここでの確認が重要。外部コマンドやメール通知など単独で動作させ
てみることも必要
② アクティブモードで起動するように設定する。(
nagios.cfg ) 通知?
③ 起動と同時にサービスチェックを行わないように設定する。( nagios.cfg ) execute_service_checks=0
④ エクスターナルコマンドが使えるように設定する。( nagios.cfg
) check_external_commands=1
⑤ パッシブサービスチェックが行えるように設定する。( nagios.cfg ) accept_passive_service_checks=1
中央サーバを構成するにあたって気にとめておかなければならない3つの重要な事項があります。
- 中央サーバには全分散サーバが監視するサービスのすべてのサービス定義を持たなくてはなりません。Nagiosは サービス定義で定義されていないパッシブチェックの結果を無視します。
- もし中央サーバを分散サーバからの結果を処理するためだけに使用するのであれば、全アクティブチェックをプログラムワイドに無効 にするexecute_service_checksディ レクティブを単純に0に設定することができます。もし中央サーバでもいくつかのサービスをアクティブチェックさせるのであれば、分散サーバが受け持つサー ビス定義のenable_active_checksオプションを0に設定します。これはNagiosがそれらのサービスに対してアクティ ブチェックを行わない設定です。
私の設定例では、中央サーバーは分散サーバーからのデータ受信だけでなく、中央サーバー自身も設定を受け持つよう設定しましたので、
execute_service_checks=1
として各項目毎の監視の制御は、services.cfg ファイルの active_checks_enabled を1か0とすることで実現しております。
|
define service{ active_checks_enabled
1 ; Active service checks
are enabled |
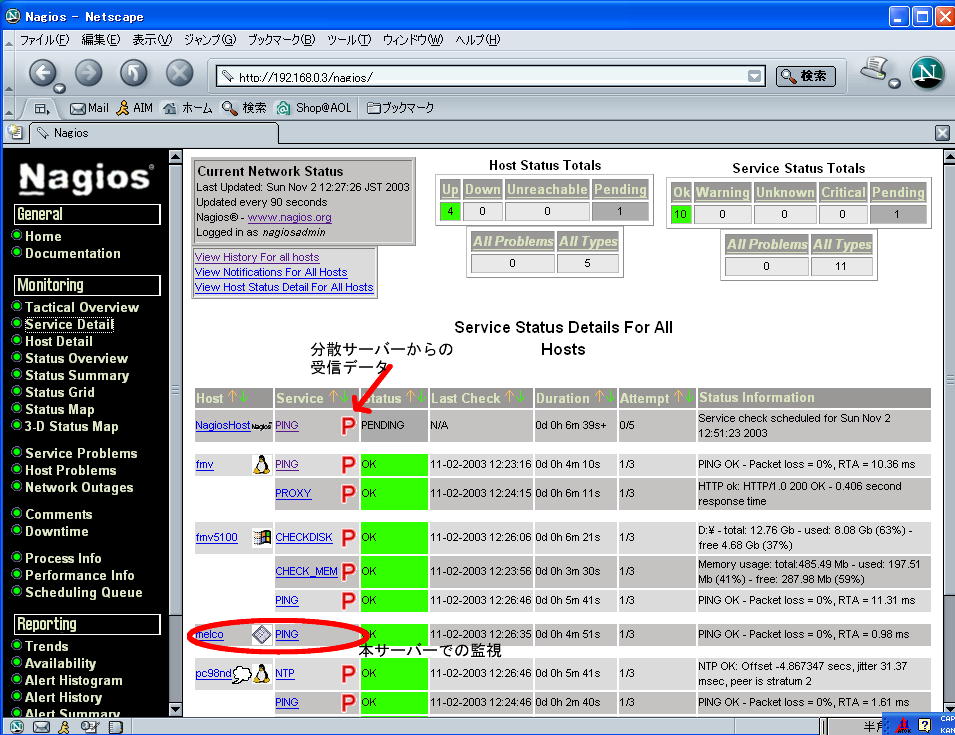
これによる監視画面の例を以下に示す。分散サーバーによる監視データにはPのマークがついている。
このPは nagios.cfg
における retain_state_infomation をoffとしなければ表示されなかった。なぜだろう。
・retain_state_information=0
・use_retained_programs=0
が必要の
ようである。
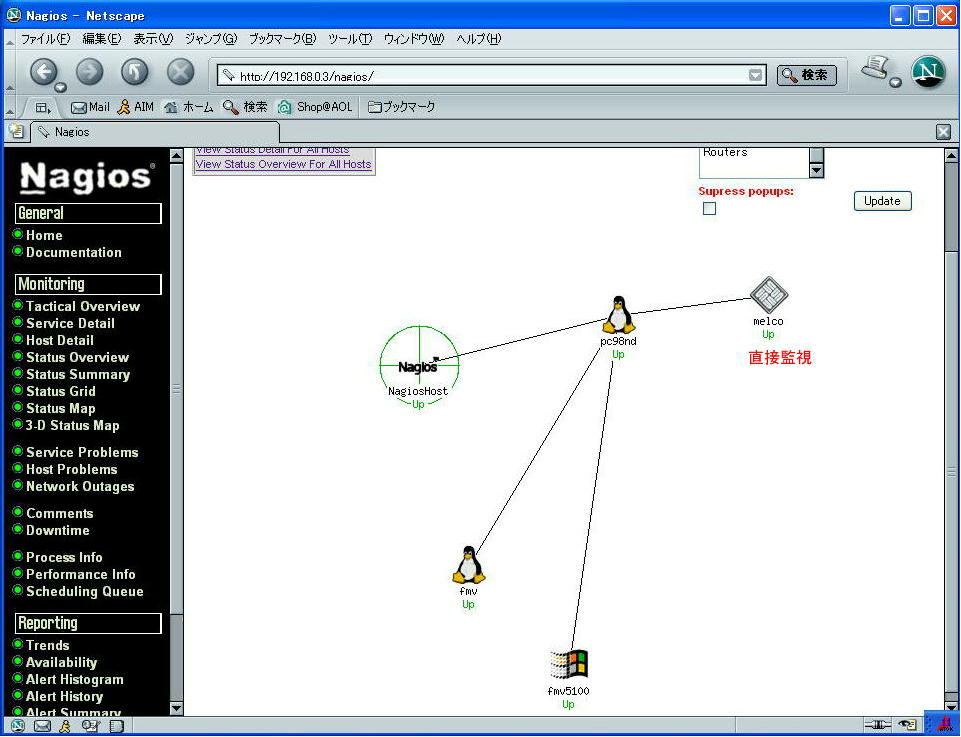
また、マップ表示画面においても、 hosts.cfg ファイルで parent
設定をすることで遠隔監視項目と直接監視項目をつなぐことが出来る。
CMSの設定でDMSと異なるのは以下の事項である。
| 1.ホストの定義で「ホストチェックコマンド」を定義しない。 2.サービスの定義で「監視時間帯」を「none」にする |
その理由は、Nagiosは、定期的にホストチェックコマンドを実行 するのではなく、監視するサービスに何らかの異常が発生したときに実行します。
そこで、監視対象上のあるサービスに異常が発生した場合、その情報がNSCAを通じてCMSに送られてくると、CMSは自らのhosts.cfgに定義さ れているホストチェックコマンドを実行しようとします。
ところが、CMSには該当アドレスを持つホストは接続されていませんので、ホストチェックコマンドは「UNREACHABLE」となってし まいます。
そして、その異常ホストが正常に戻った場合、その情報に基づき、CMSは再度ホストチェックコマンドを実行しますが、やはり「UNREACHABLE」の ままとなり、それ以降は「UNREACHABLE」状態が表示され続けてしまいます。
これを回避するために、CMS上ではホストチェックコマンドを定義しないでおきます。
コメント化または削除
#check_command check-host-alive
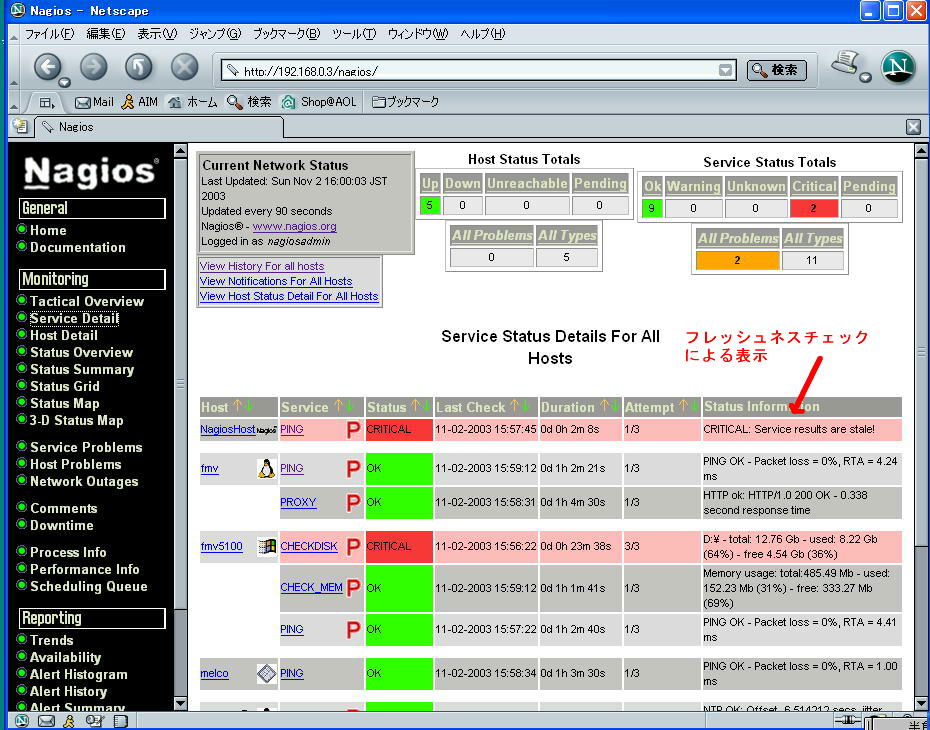
フレッシュネスチェック
Nagiosはサービスチェックの結果を"フレッシュネス"チェックする機能があります。この機能はリモートホストが中央サーバへパッシブチェックの結 果を送ってこなくなったと言う状況から保護します。"フレッシュネス"チェックの その目的は分散サーバから送られるパッシブサービスチェックと中央サーバ上の通常のアクティブチェックの結果を"確実に"することです。もし分散サーバか らのサービスチェックの結果が"期限切れ"状態であったら、Nagiosは中央監視サーバから強制的にそのサービスをアクティブチェックするよう設定しま す。
さて、これをどうやってやるか?ですが、分散サーバで監視をするサービスに中央サーバ上で次のように設定します・・・。
- サービス定義のcheck_freshnessオプションを1に設定し、そのサービスの"フレッシュネス"チェッ クを有効にします。
- サービス定義のfreshness_thresholdオプションに(分散サーバから送られてくる)サービス チェックの結果がどれぐらい"フレッシュ"かの値を設定します(秒単位)。
- サービス定義のcheck_commandオプション中央サーバからのアクティブサービスチェック用のコマンドを 設定します。
Nagiosはフレッシュネスチェックが有効になっている全サービスの結果を定期的に"フレッシュ"かどうかチェックします。それぞ れのサービス定義のfreshness_thresholdの 値がサービスチェックの結果が"フレッシュ"かどうか判断する基準になります。例えば、あるサービスのこの値を300に設定したとしたら、Nagiosは サービスチェックの結果が3分(300秒)より古ければそれは"期限切れ"と考えます。freshness_thresholdオプション の値を設定しない場合、Nagiosはnormal_check_intervalもしくはretry_check_intervalオ プションのどちらかから自動的に"フレッシュ"かどうか計算します(計算値はそのサービスがどんなステー トタイプかに依存します)。もしそのサービスチェックの結果が"期限切れ"であったならば、Nagiosはそのサービスのサービス定義のcheck_commandオ プションで指定したサービスチェックを実行します。
中央サーバからそのステータスをアクティブチェックできるようにサービス定義の check_commandオプ ションをして いしなくてはならないことを覚えておいてください。通常、このチェックコマンドは実行されることはありません(なぜならそのサービスはプログラムワイドも しくはその特定のサービスでアクティブチェックが無効にしているから)。フレッシュネスチェックが有効の際は、Nagiosはもしプログラムワイド およびその特定のサービスでアクティブチェックが無効になっていたとしてもそのサービスのステータスをこのコマンドでアクティブチェックします。
もし、中央監視サーバからのアクティブチェックコマンドを定義できない場合(もしくは設定することが困難だと判明した場合)、全サービスの check_commandオ プションに単純に警告ステータスを返すダミースクリプトを設定します。 ここにサンプルスクリプトを掲載します。定義するコマンド名を 'service-is-stale'としてサービス定義のcheck_commandに設定することを想定しています。定義は次のような 感じです・・・
define command{
command_name service-is-stale
command_line /usr/local/nagios/libexec/staleservice.sh
}
次のようなstaleservice.shスクリプトを/usr/local/nagios/libexecに 起きます。
#!/bin/sh |
Nagiosがそのサービス結果が期限切れを検知したら、service-is-staleコマンドである/usr/local/nagios/libexec/staleservice.shを
実行し、
そのサービスを警告状態にします。これにより通知が送信され、担当者は問題を認知するしょう。
| # Service definition define service{ use generic-service ; Name of service template to use host_name NagiosHost service_description PING is_volatile 0 check_freshness 1 ---フレッシュネスチェックをonとして freshness_threshold 120 データ更新の確認時間を指定する。 check_period 24x7 (単位は秒) max_check_attempts 3 normal_check_interval 30 retry_check_interval 1 contact_groups linux-admins notification_interval 120 notification_period 24x7 notification_options c,r check_command service-is-stale } active_checks_enabled 0 ; Active service checks are enabled ここは遠隔監視項目であるので当然0である。 |
監視データが指定した時間こない場合は、上で指定したようなメッセージか表示され、これが max_check_attempts で指定した回数を越えるとメールが発せられる。
パッシブ通知が停止した時の通知メール。Additional Info に所定のメッセージが挿入されている。
Notification Type: PROBLEM |
●気がついた事項
1.Nagios のメールコマンドはmisccommand.cfg で規定しているが/usr/bin/mail となっているためRedHatではその場所にはmailコマンドがない。コンパイルの時に環境に合わせて セットされているようであり、Turbolinuxでの設定をコピーしたのがいけなかったようである。
2.セントラルサーバーでのnotificationの判断は、セントラルサーバーで認識した確認回数を超過したときである。
従って発報中の事象を途中でキャッチした時は異常時の1分おきの確認は行われず通常の間隔による確認となるので時間がのびる。